
Design Tools
[php snippet=10 param=”selected=databases”]
Anthropometric Databases Guidelines
Numerous organizations around the world routinely conduct anthropometric surveys of different populations (e.g., military, civilian, etc.) and organize the information into databases. In the surveys that look to accurately represent the compositions of these populations (henceforth referred to as “reference populations”), the subjects are sampled based on demographic variables such as their age, gender, race, ethnicity, etc. The detailed anthropometric and demographic information and the large amounts of information contained in the databases make them valuable design tools.
Designers may employ either of the following two approaches when using an anthropometric database:
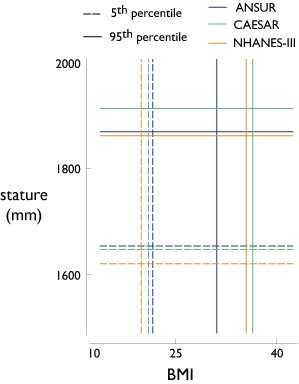
- Performing accommodation analyses directly on the reference population and extending the results to the target user population. This approach is faulty on three counts: a) it requires assuming that the reference and target populations are similarly composed, as measured by the distributions of demographic variables, b) it neglects the impact of temporal changes in the reference population anthropometry, and c) it fails to consider other reasons (e.g., high fitness levels and the absence of pregnant women in military populations) for possible differences in anthropometric distributions. The figures illustrate the differences in the compositions of three databases.
- Utilizing various techniques (e.g., principal components analysis, the regression with residual variance methodology) to extrapolate the relationships found to exist in the reference population anthropometry to the target user population. Doing so allows for the estimation of user population anthropometry; accommodation analyses may be carried out on these estimates.
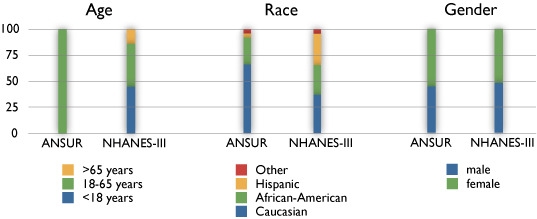
Three anthropometry databases are frequently used in research in the OPEN Design Lab:
-
NHANES
The focus of the three National Health Examination Surveys (NHES) was the civilian population of the United States from 1959 to 1970. NHES was succeeded in 1971 by the National Health and Nutrition Examination Survey (NHANES) run by the Centers for Disease Control and Prevention (CDC). NHANES I, II, and III were compiled in the years 1971-1975, 1976-1980, and 1988-1994, respectively. Of late (1999-2006), NHANES databases have been compiled every two years in order to avoid temporal errors in anthropometric analyses. However, they are not comprehensive, and are characterized by a dearth of anthropometry in addition to stature and BMI.
-
ANSUR
The 1988 U.S. Army Anthropometry Survey (ANSUR) is widely used, thanks to: a) the large number of anthropometry contained in it and b) the use of techniques such as population oversampling and statistical matching in its creation, something that allows for future army populations to be simulated by adjusting the demographic factors as required. See the DTIC website for this data.
-
CAESAR
The Civilian American and European Surface Anthropometry Resource (CAESAR) is the first database to contain data from 3-D body scans in addition to conventional 1-D measures. The subjects are random North American and European volunteers, so CAESAR is not representative of any particular population. (See Blackwell, S., Brill, T., Boehmer, M., Fleming, S., Kelly, S., Hoeferlin, D., Robinette, K., 2008, “CAESAR Survey Measurement and Landmark Descriptions”, Air Force Research Laboratory, Wright-Patterson AFB, OH)
Other surveys from around the world include Germany’s MikroZensus, Japan’s Human Engineering for Quality of Life surveys, and the Health Survey for England. The use of these databases is simplified by numerous tools that are designed to process anthropometric information and present it in more readily-usable forms. Examples of such tools are myAnthro, a source for NHANES and ANSUR data, and PeopleSize 2008 (Open Ergonomics Ltd.), which generates anthropometric estimates for different target user populations.
